All Views /
Views:
A Materials Data Curation System - Development of a framework core for Materials 4.0 in academia
by Dr Ben Thomas, MAPP Research Associate in The Department of Materials Science and Engineering at the University of Sheffield.
Materials 4.0 is currently very high up the materials research agenda. Dr Thomas explains how we are adopting digital tools and technologies in manufacturing and developing a materials data framework.
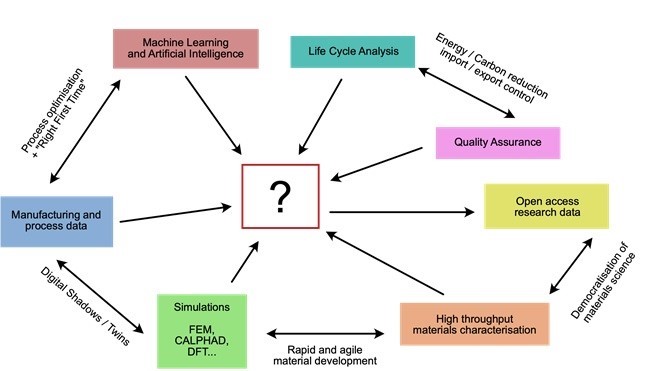
Materials science is a data-heavy field. As researchers we are constantly creating various types of data; from static 2D images of samples from microscopes, text files of time series data from mechanical tests through to high-velocity sensor data in additive manufacturing and complex four-dimensional data sets from X-ray computed tomography. Even if we don't physically touch a material we might be generating phenomenal amounts of data from atomistic simulations, finite element models of manufacturing processes or implementing complex deep learning algorithms to find hidden meaning from historical experiments.
All of this data has an intrinsic value, which for materials science is based on factors such as the manufacture of novel materials, sample preparations and time expensive experiments conducted by teams of researchers funded by taxpayers. The same can be said for industry, where profit margins can be eaten up by lengthy development cycles, extensive sample testing and quality control procedures. Research data can also have a tremendous latent value when we consider how the use of machine learning algorithms can leverage extra knowledge and understanding. Further value is embedded when data is used for quality assurance and tracing materials throughout their life cycle; tracking energy/carbon input and environmental impact at each process stage.
It has long been recognised that effective data management can be the key to improving efficiency in materials research and opening up its added value. By making sure that data is appropriately labelled and archived, future researchers can build on previous results and prevent unnecessary replication of experiments. Academia struggles in this regard due to data being poorly annotated and archived. A high turnover of specialist researchers results in experimental work being unnecessarily repeated or mistakes that could have been learned from continuing to occur. Even existing data could be hidden in paper reports, publications behind paywalls, Excel spreadsheets or text files hidden on private hard drives. Industry are already very good at avoiding this by making use of centralised IT systems, quality control frameworks and resource management systems to ensure efficient data practices. The inherent value in a company's product development data is seen as a critical asset with a tangible monetary value. Despite these good practices, industrial materials knowledge is often restricted to the domain of their products. Companies don't have access to sufficient data or knowledge to be truly agile in their development of new materials or applications.
Academia's model for materials data management has several major flaws. Academia as a whole is heavily biased towards a model of written publications for the communication of experimental data. Such a model means that complex raw data is hidden within charts in PDF documents and heavily manipulated to normalise graph axes or by using poorly reported data analysis techniques. This makes data reproduction incredibly difficult and prevents the scientific community from effectively appraising research outputs or data analysis steps. Thankfully there has been a shift in recent years with the introduction of journals dedicated to the publication of methods and datasets. There is also now a push by funding bodies to require research teams to share the data behind their publications in raw, open-access formats; a requirement that is also mirrored by some publishers.
Open access data archives are now beginning to spring up everywhere, and they enable researchers to share their datasets with others around the world. These systems, however, have to accommodate a wide range of data types and working practices, which results in the most viable archival format consisting of a 'dump' of zip files with a readme or spreadsheet file to describe what is in the folders and files. People wanting to access this data find themselves in a position of having to manually curate all this data into their own formats or to abandon access attempts altogether. There is a general consensus that about 80% of a data analyst's time is spent identifying, cleaning and transforming data to fit into their algorithms. If computing hardware is becoming ever more powerful and easier to access, data curation tasks will continue to be a limiting factor that stifles rapid innovation.
The assertions in the previous paragraphs are, in some cases, over-generalisations and many areas of science, such as physics, biochemistry and pharmacology, are already dealing with these issues very effectively. However, I am sure that many academics who read this can relate to the feeling of despair when knowledge is lost through factors such as poor experimental design, sparse data logging, hardware failures and high turnover of research or technical staff.
Within MAPP, all of these issues have been brought to the fore. MAPP is a multi-institutional, multi-year project with researchers coming together to feed their expertise into solving common issues within powder metallurgy and polymer sciences. The problems being addressed across multiple length scales and areas of materials expertise; from fundamental powder flow behaviour to complex thermo-mechanical powder processing. When you add in the development of machine learning algorithms to expedite knowledge generation, process optimisation and control of the powder process, you can see how important data generation, acquisition and dissemination is to the project.
Working in conjunction with the Henry Royce Institute at the University of Sheffield, MAPP is prototyping its own materials data framework as a way to solve the complex issues written above. The scope of the work is to provide a platform to enable researchers to easily input, curate, query and analyse the multitude of complex data that is being generated across the wide breadth of materials science. This includes things such as simple metadata for material samples, micrograph images, thermal camera data from additive manufacturing builds and raw data from characterisation equipment; all linked together to facilitate querying and understanding. Another major part of the development is the integration of live process data from new equipment brought by the Henry Royce Institute as well as legacy equipment. Through the implementation of conventional digital manufacturing standards, frameworks for the Industrial Internet of Things, bespoke sensors and novel implementations of web technologies, we hope to demonstrate a range of case studies across the highly demanding research environment.
To design such a system, we have to take several things into consideration; some of which are common across all of materials science/manufacturing and some are unique to an academic research environment.
- The system should be cloud-based, highly scalable, fault-tolerant and built to be modular. The modern micro-services approach has many benefits over a monolithic system as it allows extra modules or features to be added while minimising the impact on the existing system.
- It should be open-source and built on modern languages and frameworks to ensure there is a large potential developer base. This also ensures that code auditing is possible to allow maximum transparency or for subsystems to be easily implemented across other parts of academia and industry. This being said, no one programming language is the best fit for all use cases.
- The system should make sure of common data and communications standards to enable the transferal of knowledge between research and industry. All the hard work of developing these standards has already been done and there is no need to 'reinvent the wheel'.
- The system needs to talk a common language across all of its subsystems and external integrated systems. This has been a constant factor in previous attempts in making such a framework. Using data formats such as XML or JSON allows both the raw data and the descriptive metadata to be stored together. The data is then readable by both humans and computers to allow the development of application programming interfaces based on REST or GraphQL to convert data reliably between the internal and external systems.
- Usability for humans needs to be a primary concern. Researchers need to be able to enter data in a very quick and simple way to ensure high levels of compliance and data quality. If possible, automation of data acquisition is ideal to eliminate the potential for human errors or laziness.
- As the system is designed to be cloud-based, user interfaces should be accessible via web browsers. In particular, the web app(s) should be 'mobile friendly' to enable researchers to input data from phones and tablets at the point of acquisition. This is even more important for legacy systems that might be running non-networked control PCs. A mobile-first design will increase user compliance and add to improving workflows rather than hindering them.
- The system needs to be equally secure and open to prevent critical data from being accessed by unauthorised parties, to prevent data vandalism but also to provide an easy way to share publicly accessible data with other researchers. Public/private REST APIs with tight access controls ensure data is shared in the correct way to appease individual researchers, funding bodies and industry.
- The inclusion of modular peripheral systems; such as Edge Computing units should be built on open-source frameworks and, if possible, with open-source hardware. Documenting and communicating these subsystems can help to drive the understanding and adoption of modern digital techniques both within academic and industrial environments. In some cases, closed-source hardware may be preferable for stability or security reasons but they should also be freely available and their adoption not cost-prohibitive.
- Huge quantities of raw data need to be acquired and made easily available for active research. However, there will be a constant push to reduce the required data storage by the use of 'computing at the edge' as we improve our ability to dimensionally reduce the data and archive only the data that is critical to future learning.
There are several existing cloud-based platforms that have been developed to meet similar goals to these and have been used to inform the current design. While we do not want to reinvent the wheel, there are a number of issues with these existing systems that make them less than ideal for an experimentally heavy research environment. These include:-
- No ability to upload detailed, raw experimental data from equipment with relevant metadata. Allowing too much user interpretation of results can mask bad data from critical appraisal.
- Can only add single property values from literature. This can be good to curate existing, published data from scientific papers but masks the raw data behind many layers of data analysis.
- Archives data but does not provide users with immediate benefits such as complex data visualisation. This is seen as a critical point in assessing the adoption of a new system into existing workflows. Users will be more inclined to use a system for their data if it gives them an immediate, tangible benefit in return.
- Closed source or paid licensing, which can severely limit the impact of data within the system.
We are currently in the design and prototyping phase and are testing several sub-systems within the University of Sheffield. These sub-systems are covering materials data across the full research workflow from material creation, alloy design and manufacture to process window investigations and final part characterisation. The backbone to everything is a common language based on JavaScript Object Notation (JSON) where all sub-systems (and humans) can understand exactly what data is expected on the inputs and outputs. Influence is taken from a number of existing systems such as Citrine Informatics 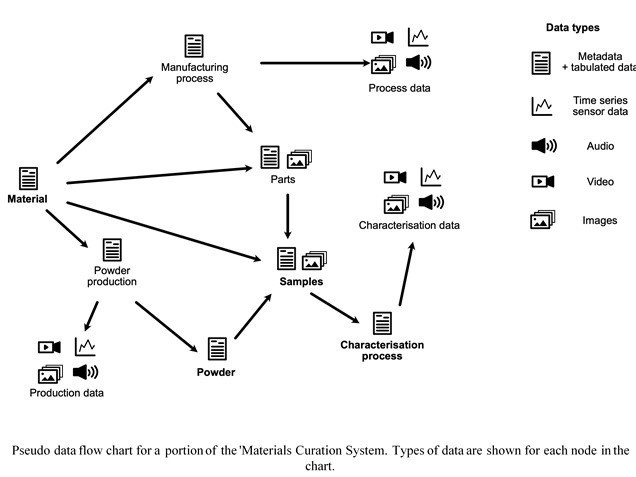
The data backend is based around the NoSQL paradigm where, instead of 'rows' in a spreadsheet, each material is a 'document' that can contain lots of nested information. There are also linked data schemas that dictate a particular format for the nested data to ensure it is validated properly. Just like the material objects, all of the linked schemas within the system have similar formats, which allows it to evolve dynamically during this development phase without the need for extensive data migrations. Each of the [Value] inputs contain the ability to link to a specific material condition as well as inputting either a reference-linked value from literature or experimental values with associated temperature and pressure conditions. We have also included the ability to flag property values, creating a user-driven data sanitisation system. If values are observed to be erroneous it is possible to flag these to the original user and 'quarantine' them until their authenticity has been proven. This further improves the data quality in a retrieved dataset.
Although the backbone to the system is the material 'objects', a major distinguishing feature of ours is the integration of raw experimental data. The easiest way to do this would be to create a range of data 'ingesters'; peripheral code functions that take an input of text files from equipment and translate them into the predefined format for the core system to store. This relies on users manually inputting the data and provides several opportunities for the 'human-factor' to degrade data quality. Because we have physical access to all the equipment that we intend to integrate, it is possible to automate a large portion of this data transfer, ensuring data integrity and compliance.
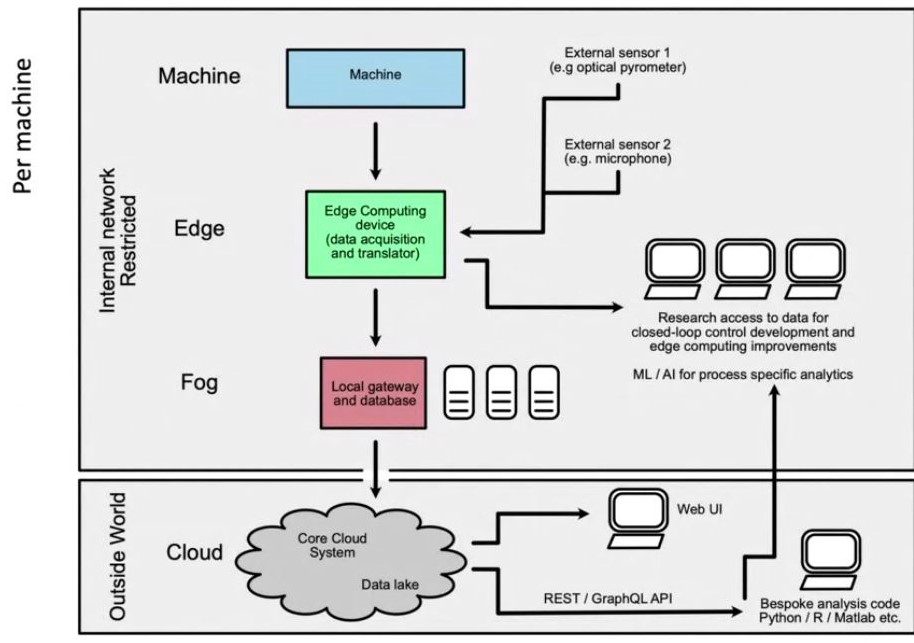
A good example is the process data from a laser powder bed fusion (LBPF) additive manufacturing machine. The machine operator will typically fill in a list of build parameters on a spreadsheet and prepare the build in specialist CAD software e.g. Autodesk NetFabb. The powder and build program are put into the machine and it is set to build. Once complete, the parts are removed, cleaned and sent for post-processing. At all stages of this process, it is possible to haemorrhage data, through poor recording of build parameters, not tracking powder usage, not acquiring peripheral data from extra sensors and not characterising/debugging failed parts. By linking the machine use logs, automating data acquisition of external sensors, flagging failed parts and ensuring data input from users into an easy-to-use common system it is possible to ensure a minimum data standard for all LPBF builds. This in turn leads to good quality datasets that subsequent users can build on.
There are three key arguments behind maximising automation in this environment: -
- Freeing up researcher time to focus on the science of the materials and processes and not data management.
- Maximise data acquisition and quality, preventing unnecessary repeat experiments. Machine learning can require vast levels of high quality, labelled data, which is not always possible to attain with distributed teams or with high personnel turnover,
- Minimise change management - breaking through resistance to workflow changes by minimising changes to the users’ regular routines.
Stay tuned for more blog posts highlighting progress on key sub-projects of this Materials Data Curation framework. There will also be a range of other posts and tutorials detailing lessons learned along the development cycle and on teaching key concepts of the framework's infrastructure and associated workflows.
Key projects will include:-
- Aftermarket high-speed data acquisition, edge computing and cloud integration for additive manufacturing.
- A distributed image analysis framework using deep learning techniques to democratise automated microstructure quantification.
Dr Ben Thomas, a Research Associate in the Department of Materials Science and Engineering at the University of Sheffield, has a keen interest in data management, analysis, visualisations and data workflows within scientific research. He studied for his PhD in the powder metallurgy of titanium alloys at the University of Sheffield and an undergraduate Masters degree in Physics and Astronomy. He has worked on a number of large projects involving the solid state processing of metal powders.
More:
Views
-
Joint Thai-UK research project to exchange knowledge and upskill Thai academics and engineers in optical manufacturing.
-

-
